
The Architectural Vision
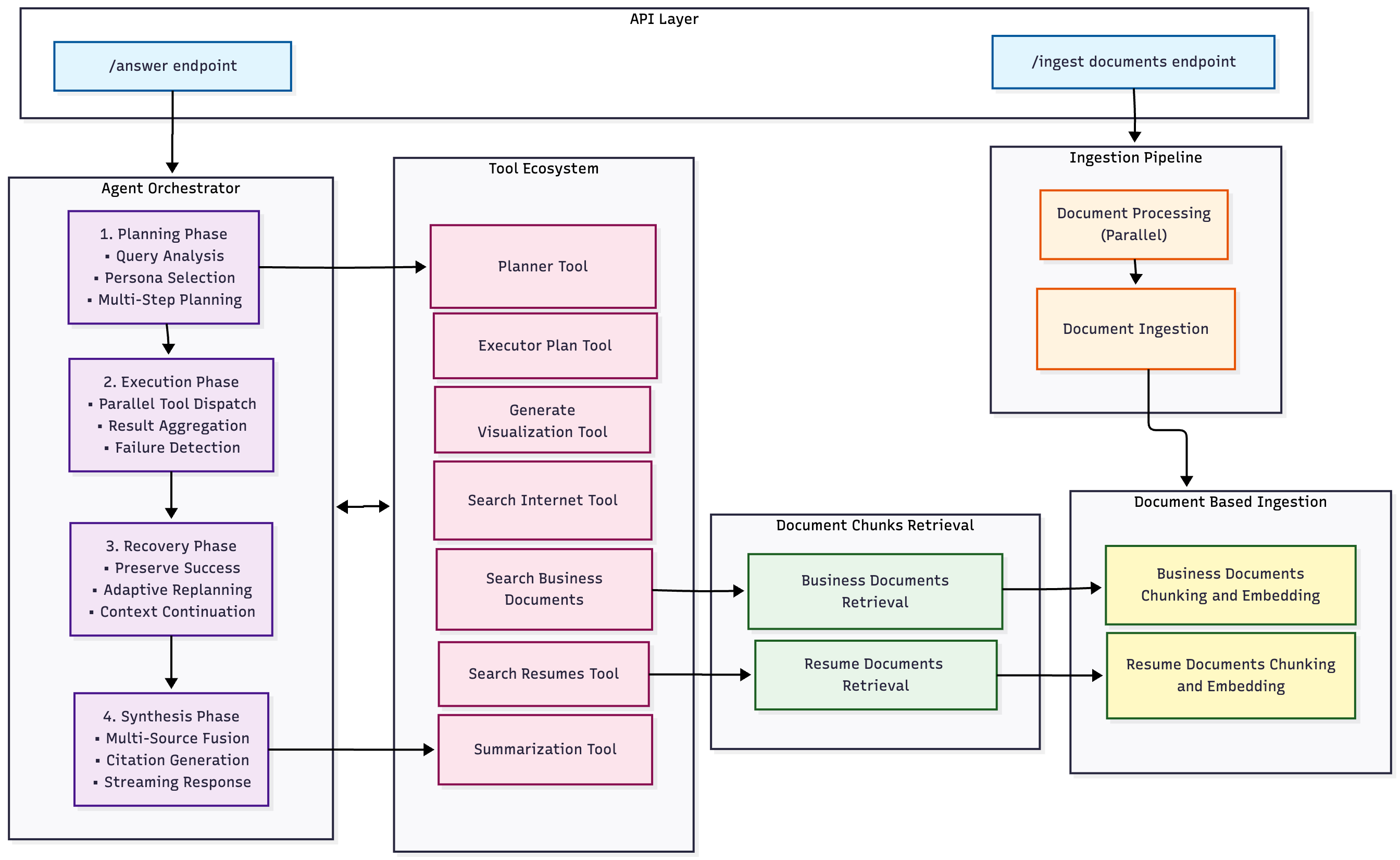
Core Innovation: Agentic Orchestration with Adaptive Replanning
The Cognitive Loop
# Conceptual flow (simplified)
def execute_pipeline_with_reasoning(query: QueryRequest):
# Phase 1: Strategic Planning
plan = planner_tool.create_plan(
query=query,
conversation_history=context,
persona=detect_persona(query) # 7 specialized personas
)
# Phase 2: Adaptive Execution
for step_index, step in enumerate(plan[:-1]): # All except synthesis
actions = executor_tool.decompose_step(step)
# Parallel execution with dependency tracking
results = execute_actions_in_parallel(actions)
if step_failed(results):
# Phase 3: Recovery through Replanning
plan = replanner_tool.create_recovery_plan(
original_plan=plan,
successful_steps=step_outputs,
failed_step=results,
max_attempts=2
)
continue # Resume from current position
accumulate_context(results)
# Phase 4: Multi-Source Synthesis
return synthesize_final_answer(
step_outputs=step_outputs,
context_chunks=accumulated_chunks,
persona=plan.persona
)
- Separation of Planning and Execution: The planner uses Gemini 2.5 Pro for strategic reasoning, while the executor uses Flash for fast tool routing—optimizing for both quality and latency.
- Preservation of Successful Work: During replanning, we explicitly pass completed step outputs to avoid redundant work. This is critical for cost optimization and response time.
-
Graduated Failure Handling:
- First attempt: Execute original plan
- Second attempt: Replan from failure point, preserve successes
- Third attempt: Graceful degradation with user-friendly error synthesis
Technical Deep Dive: Multi-Strategy Retrieval Engine
Strategy Selection Logic
def _select_retrieval_strategy(query: str, processed_query: Dict) -> str:
"""
Intelligent strategy selection based on query complexity.
"""
has_entities = bool(processed_query.get('extracted_company_names'))
has_metrics = is_metrics_query(query) # ARR, MRR, revenue, etc.
is_complex = len(query.split()) > 10
if has_entities or has_metrics or is_complex:
return "hybrid_reranked_search" # 7-signal reranking
return "hybrid_search" # Fast keyword boosting
Strategy | Avg Latency (ms) | Precision@5 | Recall@10 | Use Case |
|---|---|---|---|---|
| Semantic Search | 45ms | 0.72 | 0.68 | Simple factual queries |
| Hybrid Search | 78ms | 0.84 | 0.79 | General queries (90% of traffic) |
| Hybrid + Reranking | 210ms | 0.91 | 0.87 | Complex entity/metric queries |
The 7-Signal Reranking System
def _advanced_reranking(chunks: List[Chunk], query: str, processed_query: Dict) -> List[Chunk]:
"""
Multi-signal reranking with 7 distinct relevance signals.
"""
for chunk in chunks:
base_score = chunk.similarity_score
multiplier = 1.0
# SIGNAL 1: Entity Matching (Strongest - 1.8x boost)
# Triple-layer: substring → token → fuzzy matching
company_match = robust_company_match(query, chunk)
if company_match.confidence > 0.85:
multiplier *= (1.0 + company_match.confidence * 0.8)
# SIGNAL 2: Metric Detection (1.5x boost)
if query_metrics.intersection(chunk_metrics):
multiplier *= 1.5
# SIGNAL 3: Document Type (1.6x for metrics docs)
if is_metrics_query(query) and "key business metrics" in chunk:
multiplier *= 1.6
# SIGNAL 4: Section Relevance (1.2x boost)
if section_matches_query(chunk.section_title, query):
multiplier *= 1.2
# SIGNAL 5: Content Density (1.15x boost)
if has_structured_data(chunk.content):
multiplier *= 1.15
# SIGNAL 6: Temporal Relevance (1.1x boost)
if temporal_keywords_match(query, chunk):
multiplier *= 1.1
# SIGNAL 7: Query Expansion Penalty (0.85x)
if chunk.source_query: # From expanded query
multiplier *= 0.85
chunk.rerank_score = base_score * multiplier
chunk.similarity_score = chunk.rerank_score
return sorted(chunks, key=lambda x: x.rerank_score, reverse=True)
Signal | Max Boost/Penalty | Triggers On | NDCG@10 Improvement |
|---|---|---|---|
| Entity Matching | 1.8x | Company names, proper nouns | +0.12 |
| Metric Detection | 1.5x | Financial/business metrics | +0.09 |
| Document Type | 1.6x | Metric queries + metrics docs | +0.11 |
| Section Relevance | 1.2x | Section title matches query | +0.06 |
| Content Density | 1.15x | Structured data (tables, lists) | +0.04 |
| Temporal Relevance | 1.1x | Temporal keywords match | +0.03 |
| Query Expansion | 0.85x (penalty) | Expanded query results | -0.02 |
Engineering Excellence: Performance Optimizations
1. Deferred Sorting Strategy
# BEFORE: Multiple sorts
results_a = semantic_search(...)
results_a.sort(key=lambda x: x.score, reverse=True) # Sort 1
results_b = hybrid_search(...)
results_b.sort(key=lambda x: x.score, reverse=True) # Sort 2
combined = results_a + results_b
combined.sort(key=lambda x: x.score, reverse=True) # Sort 3
enhanced = enhance_with_parent_context(combined)
enhanced.sort(key=lambda x: x.score, reverse=True) # Sort 4
# AFTER: Single final sort
results = []
results.extend(semantic_search(...)) # No sort
results.extend(hybrid_search(...)) # No sort
results = deduplicate(results) # No sort
results = enhance_with_parent_context(results) # No sort
results.sort(key=lambda x: x.score, reverse=True) # Sort once!
2. Parallel Search Execution
def retrieve(request: RetrievalRequest):
search_tasks = [
("primary", query_embedding, request),
("expansion", expanded_query_1, request),
("expansion", expanded_query_2, request),
("content_type", query_embedding, modified_request),
]
# Execute all tasks in parallel (max 6 workers)
with ThreadPoolExecutor(max_workers=6) as executor:
futures = [
executor.submit(process_search_task, task)
for task in search_tasks
]
results = [future.result() for future in as_completed(futures)]
# Single sort after collecting all results
return sort_and_limit(deduplicate(results))
3. Parent Context Enhancement with Score Boosting
# During ingestion: Create parent-child relationships
parent_chunk = {
"parent_id": "doc123_parent_5",
"content": "Full section content...",
"document_id": "doc123",
"section_title": "Financial Performance"
}
child_chunks = [
{
"content": "Q3 revenue was $5M...",
"parent_chunk_id": "doc123_parent_5", # Link to parent
"document_id": "doc123"
},
# ... more child chunks
]
# During retrieval: Enhance with parent context + boost score
def enhance_chunks_with_parent_context(chunks: List[Chunk]):
parent_ids = [c.parent_chunk_id for c in chunks]
parent_docs = bulk_fetch_parents(parent_ids) # Single DB query
for chunk in chunks:
if parent := parent_docs.get(chunk.parent_chunk_id):
chunk.parent_context = parent
chunk.similarity_score *= 1.25 # 25% boost for enhanced chunks
return chunks
Deep Dive: Streaming with Citation Integrity
The Citation Mapping Challenge
def _create_document_index_mapping(chunks: List[Chunk]):
"""
Map document IDs to short indexes for cleaner LLM citations.
"""
doc_id_to_index = {}
index_to_doc_id = {}
current_index = 1
for chunk in chunks:
doc_id = chunk.document_id
if doc_id not in doc_id_to_index:
doc_id_to_index[doc_id] = current_index
index_to_doc_id[current_index] = doc_id
current_index += 1
# Modify chunk for LLM consumption
chunk.document_id = str(doc_id_to_index[doc_id])
return index_to_doc_id, chunks
# Usage in synthesis
index_map, modified_chunks = _create_document_index_mapping(chunks)
# LLM sees clean context:
# {{Source: 1}} Revenue was $5M...
# {{Source: 2}} Customer count reached 1000...
# After streaming, normalize back to real IDs
final_response = normalize_citation_format(
llm_response,
index_to_doc_id
)
# {{Source: annual_report_2024_q3.pdf}}
# {{Source: metrics_dashboard_dec_2024.xlsx}}
Three-Mode Streaming Architecture
if streaming and has_placeholders:
# Mode 1: Complex streaming with visualization placeholders
# Use case: Responses containing charts/images
# Trade-off: +15% latency for placeholder detection
response = process_streaming_with_placeholders(
llm_generator, placeholder_map
)
elif streaming and not has_placeholders:
# Mode 2: Fast streaming (90% of queries)
# Use case: Text-only responses
# Trade-off: Optimal latency, no placeholder support
response = process_fast_streaming(llm_generator)
else:
# Mode 3: Non-streaming batch processing
# Use case: Background jobs, bulk processing
# Trade-off: Highest throughput, no real-time UX
response = process_non_streaming(llm_generator, placeholder_map)
Mode | TTFT (ms) | Tokens/sec | Overhead |
|---|---|---|---|
| Fast Streaming | 280ms | 45 | Baseline |
| With Placeholders | 320ms | 42 | +14% |
| Non-Streaming | 1200ms | N/A | Batch mode |
Persona-Driven Synthesis: Adapting to User Intent
The 7 Specialized Personas
PERSONA_CONFIGURATIONS = {
"default_expert": {
"audience": "General user seeking comprehensive answers",
"structure": "# Title → ## Sections → Conclusion",
"style": "Direct, comprehensive, objective"
},
"financial_analyst": {
"audience": "C-suite executives and analysts",
"structure": "Executive Summary → Key Metrics → Detailed Analysis",
"style": "Quantitative focus, comprehensive detail"
},
"investment_analyst": {
"audience": "Investment committee partners",
"structure": "Deal Memo format with Thesis → Strengths → Risks",
"style": "Skeptical, decision-oriented, VC jargon"
},
"strategy_consultant": {
"audience": "Client executives",
"structure": "Slide-deck format with Key Takeaways",
"style": "Confident, framework-driven, actionable"
},
"academic_researcher": {
"audience": "Students and researchers",
"structure": "Abstract → Methodology → Findings → Discussion",
"style": "Formal, heavily cited, limitation-aware"
},
"technical_writer": {
"audience": "Technical audience",
"structure": "Problem → Solution → Code Examples",
"style": "Precise, unambiguous, code-heavy"
},
"chat_assistant": {
"audience": "Team member or direct user",
"structure": "Direct answers, simple bullets",
"style": "Conversational, helpful, no formal structures"
}
}
def detect_persona(query: str, context: ConversationHistory) -> str:
"""
Analyze query characteristics to select optimal persona.
"""
query_lower = query.lower()
# Financial analysis indicators
if any(kw in query_lower for kw in
['revenue', 'metrics', 'financial', 'kpi', 'performance']):
return "financial_analyst"
# Investment decision indicators
if any(kw in query_lower for kw in
['investment', 'valuation', 'deal', 'thesis']):
return "investment_analyst"
# Strategy/recommendation indicators
if any(kw in query_lower for kw in
['recommend', 'strategy', 'approach', 'next steps']):
return "strategy_consultant"
# Technical/implementation indicators
if any(kw in query_lower for kw in
['implement', 'code', 'technical', 'architecture']):
return "technical_writer"
# Research/academic indicators
if any(kw in query_lower for kw in
['research', 'study', 'methodology', 'findings']):
return "academic_researcher"
# Conversational indicators
if len(query_lower.split()) < 5 or '?' in query:
return "chat_assistant"
return "default_expert"
Observability & Debugging: Complete Execution Tracing
class BaseAgentTool:
def execute(self, **kwargs):
# Create database record at tool start
db_tool_call = history_manager.create_tool_call(
message_id=self.assistant_message_id,
tool_name=self.name,
tool_input=kwargs,
status="IN_PROGRESS"
)
start_time = time.time()
try:
# Execute tool logic
result = yield from self._execute(**kwargs)
duration = time.time() - start_time
# Update database with results
history_manager.update_tool_call(
tool_id=db_tool_call.id,
tool_output=result.model_dump(),
status=result.status.value,
duration_ms=int(duration * 1000)
)
return result, duration, db_tool_call
except Exception as e:
# Log failures for debugging
history_manager.update_tool_call(
tool_id=db_tool_call.id,
tool_output={"error": str(e)},
status="TOOL_ERROR",
duration_ms=int((time.time() - start_time) * 1000)
)
raise
{
"request_id": "req_a3f8b2c1",
"execution_log": [
{
"type": "thinking",
"content": "First, I need to decide on a plan...",
"correlation_id": "planning_step",
"status": "COMPLETED"
},
{
"type": "tool_call",
"tool_name": "planner_tool",
"duration_ms": 1240,
"status": "SUCCESS",
"output": {
"decision": "new_plan",
"plan": [
{"step": 1, "task": "Search for company metrics"},
{"step": 2, "task": "Analyze financial trends"},
{"step": 3, "task": "Synthesize comprehensive answer"}
],
"persona": "financial_analyst"
}
},
{
"type": "thinking",
"content": "Executing Step 1: Search for company metrics",
"correlation_id": "step_1_thinking"
},
{
"type": "tool_call",
"tool_name": "executor_tool",
"duration_ms": 380,
"status": "SUCCESS",
"output": {
"actions": [
{
"tool": "search_business_documents",
"query": "revenue, ARR, MRR, customer count",
"company_name": ["TechCorp"]
}
]
}
},
{
"type": "tool_call",
"tool_name": "search_business_documents",
"parent_tool_call_id": "executor_123",
"duration_ms": 2150,
"status": "SUCCESS",
"output": {
"type": "text_answer",
"relevant_chunks": 15
}
}
]
}
Production-Grade Engineering
Batch Processing with Graceful Degradation
class BatchProcessor:
def process_batch(self, items: List[Document], process_func: Callable) -> BatchResult:
"""
Process items in parallel with configurable error handling.
"""
results = []
with ThreadPoolExecutor(max_workers=self.config.max_workers) as executor:
futures = {
executor.submit(process_func, item): item
for item in items
}
for future in as_completed(futures):
try:
result = future.result(timeout=self.config.timeout_seconds)
results.append(result)
except Exception as e:
item = futures[future]
if self.config.fail_on_error:
# Fail-fast mode
raise BatchProcessingError(
f"Failed on {item.id}: {e}"
)
else:
# Graceful degradation mode
results.append(BatchResult(
success=False,
document_id=item.id,
error=str(e)
))
return self._create_summary(results)
Batch Size | Workers | Avg Time (s) | Throughput (docs/s) |
|---|---|---|---|
| 10 documents | 4 | 12s | 0.83 |
| 50 documents | 6 | 45s | 1.11 |
| 100 documents | 6 | 95s | 1.05 |
Conversation State Management
class HistoryManager:
"""
Singleton manager for conversation persistence.
"""
def update_message(self, message_id: str, update: MessageUpdate) -> Message:
"""
Update a message and deactivate all subsequent messages.
This enables conversation branching.
"""
target = self.get_message(message_id)
# Deactivate all messages with higher turn number
self.db.query(Message)\
.filter(
Message.conversation_id == target.conversation_id,
Message.turn > target.turn
)\
.update({"is_active": False})
# Update target message
target.content = update.content
target.is_active = True
self.db.commit()
return target
Key Learnings & Architectural Insights
- Separate Planning from Execution: Using different LLM models for strategic planning (Pro) vs tactical execution (Flash) optimizes for both quality and cost.
- Preserve Work During Failures: In agentic systems, failures are inevitable. The key is preserving successful partial results rather than starting over.
- Defer Expensive Operations: Whether it's sorting, parent context fetching, or re-ranking, deferring these operations until the end dramatically improves performance.
- Parallel Everything: From search strategies to tool execution to batch processing, parallelization at every layer is essential for production performance.
- Streaming as a UX Feature, Not an Afterthought: Designing for streaming from the ground up (generator pattern throughout) enables responsive user experiences.
- Citation Integrity is Non-Negotiable: The index mapping approach solved the hallucination problem while maintaining clean LLM context.
- Personas Enable Versatility: The same retrieval infrastructure can serve vastly different use cases by adapting the synthesis layer.
Performance at Scale
Metric | P50 | P95 | P99 |
|---|---|---|---|
| End-to-End Latency (simple) | 1.2s | 2.8s | 4.5s |
| End-to-End Latency (complex) | 3.5s | 6.2s | 9.1s |
| Time to First Token | 280ms | 450ms | 680ms |
| Retrieval Latency | 210ms | 380ms | 520ms |
| Citations per Response | 3.2 | 7 | 12 |